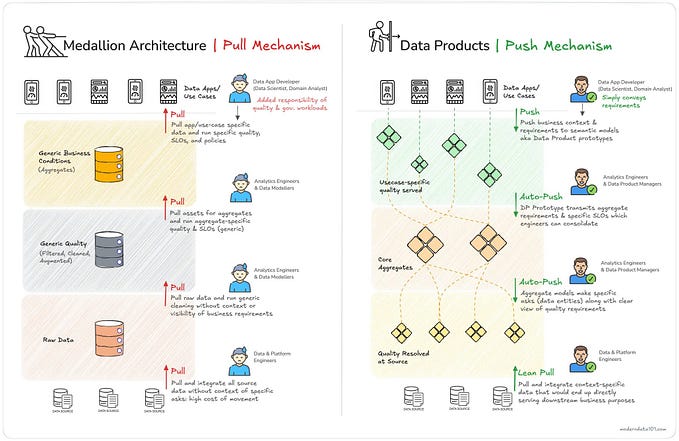
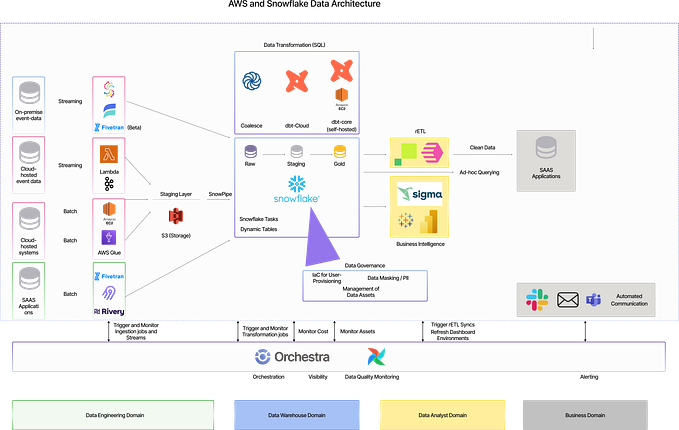
Navigating the Layers of Modern Data Platform Architecture

In this blog, we shall take a deep dive into the intricate world of data platform architecture — a crucial backbone for any tech-driven enterprise today. Whether you’re a budding data engineer, a seasoned architect, or simply a tech enthusiast, understanding the layers of a data platform is essential for grasping how big data is managed and utilized to drive decision-making and innovation.
Introduction to Data Platform Layers
A data platform is not a monolith but a composition of several layers, each dedicated to a particular function in the data handling process. Let’s explore each layer in detail and understand their roles and interactions within a typical data architecture framework.
1. Data Collection Layer
Role: The Data Collection Layer, or Data Ingestion Layer, is the gateway through which data enters the data platform. It is responsible for establishing connections with source systems and ensuring that the data is seamlessly transferred into the system, either in real-time (streaming) or in batches.
Tools and Technologies: Popular tools used in this layer include Google Cloud DataFlow, Apache Kafka, and Amazon Kinesis, which support both batch and streaming data. These tools ensure that data ingestion is efficient, reliable, and scalable to meet the needs of vast and varied data landscapes.
2. Data Storage and Integration Layer
Role: Once the data is collected, it needs a home. The Storage and Integration Layer provides a repository for this data — ensuring it is securely stored, well-organized, and readily accessible for further processing. This layer also involves transforming and merging the data to prepare it for analysis.
Tools and Technologies: For relational data, databases like MySQL, Oracle, and cloud-based solutions like Amazon RDS are prevalent. NoSQL databases such as MongoDB or Cassandra cater to more dynamic data needs. Integration tools like Talend Data Fabric and IBM Cloud Pak for Integration play a vital role in ensuring the data is coherent and primed for use.
3. Data Processing Layer
Role: This is the transformation engine of the platform. The Data Processing Layer takes raw data and turns it into something valuable. It performs data cleansing, validation, and the application of business rules to ensure that the data is accurate and suitable for analysis.
Tools and Technologies: Tools such as Apache Spark and IBM Watson Studio enable data processing at scale, supporting a plethora of operations from simple data structuring to complex data enrichment techniques. Python and R are also heavily used here for their powerful data manipulation libraries.
4. Analysis and User Interface Layer
Role: This is where data turns into insights. The Analysis and UI Layer delivers processed data to the end-users — be it through dashboards, reports, or further data science modeling. This layer must support various querying tools and programming languages to cater to diverse business needs.
Tools and Technologies: Tools like Tableau for visualization, Jupyter Notebooks for interactive programming, and APIs for real-time data access are integral to this layer. They ensure that insights derived from the data are accessible and actionable.
5. Data Pipeline Layer
Role: Overlaying the aforementioned layers, the Data Pipeline Layer acts as the circulatory system for the data platform, ensuring data flows seamlessly across all stages from ingestion to insights. This layer uses ETL (Extract, Transform, Load) processes to maintain data integrity and timeliness.
Tools and Technologies: Apache Airflow and Google Cloud DataFlow are prominent players that automate and manage the data workflows, making sure that the data pipeline is robust, error-free, and efficient.
The Symphony of Data Layers
Each layer of the data platform architecture plays a specific and crucial role in the data lifecycle. Understanding these layers and their interdependencies helps in designing systems that are not only robust and scalable but also adaptable to the ever-evolving data demands. The architecture you choose impacts the agility and intelligence of your entire operation. As you build or refine your data platforms, consider how each layer can be optimized to bring out the best in your data, driving growth and innovation.
From my experience as a data engineer over the years, I’ve witnessed firsthand how a well-architected data platform can transform raw data into actionable insights that propel business strategies. Here are a few additional thoughts on optimizing each layer to ensure your data platform is both efficient and future-proof:
- Focus on Scalability and Flexibility: Ensure that each layer can scale independently to accommodate growing data volumes and changing business needs. Use cloud-native solutions that offer flexibility and elasticity to scale resources up or down as required.
- Implement Strong Data Governance: Establish robust data governance practices to ensure data quality, security, and compliance across all layers. This includes data lineage tracking, access controls, and regular audits to maintain data integrity.
- Leverage Automation and Orchestration: Utilize automation tools to manage repetitive tasks and orchestrate complex workflows. This not only improves efficiency but also reduces the likelihood of human errors. Tools like Apache Airflow and Google Cloud DataFlow can significantly streamline data pipeline operations.
- Promote a Culture of Continuous Improvement: Encourage a culture where continuous monitoring and optimization of data processes are standard practices. Regularly review performance metrics and seek feedback from end-users to identify areas for improvement.
- Invest in Training and Development: Equip your team with the latest skills and knowledge in data engineering. Continuous learning and professional development ensure that your team can leverage new tools and technologies effectively, keeping your data platform ahead of the curve.
- Adopt a Modular Approach: Design your data platform with modularity in mind. This allows for easier updates, integration of new technologies, and minimal disruption to existing processes. Each module can be developed, tested, and deployed independently, facilitating a more agile development process.
- Focus on Real-Time Data Processing: As real-time data becomes increasingly critical for decision-making, ensure your platform supports real-time data ingestion, processing, and analytics. Technologies like Apache Kafka and Apache Spark Streaming are essential for handling real-time data flows efficiently.
By paying careful attention to these aspects, you can build a data platform that not only meets current business requirements but is also capable of evolving with technological advancements and emerging data trends. The goal is to create a robust, scalable, and adaptable data ecosystem that drives innovation and provides a competitive edge in today’s data-driven world.
References
- The Data Engineering Cookbook: The Data Engineering Cookbook
- Data Engineering Tools: https://redpanda.com/guides/fundamentals-of-data-engineering/data-engineering-tools
- IBM’s Introduction of Data Engineering: https://www.coursera.org/learn/introduction-to-data-engineering/
- Google Data Flow: https://cloud.google.com/dataflow
- Apache Kafka: https://kafka.apache.org/
- Amazon Kinesis: https://aws.amazon.com/kinesis/
- Amazon RDS: https://aws.amazon.com/rds/
- MongoDB: https://www.mongodb.com/
- Cassandra: https://cassandra.apache.org/
- Talend Data Fabric: https://www.talend.com/products/data-fabric/
- IBM Cloud Pak for Integration: https://www.ibm.com/cloud/cloud-pak-for-integration
- Apache Spark: https://spark.apache.org/
- IBM Watson Studio: https://www.ibm.com/cloud/watson-studio
- Tableau: https://www.tableau.com/
- Jupyter Notebooks: https://jupyter.org/
- Apache Airflow: https://airflow.apache.org/